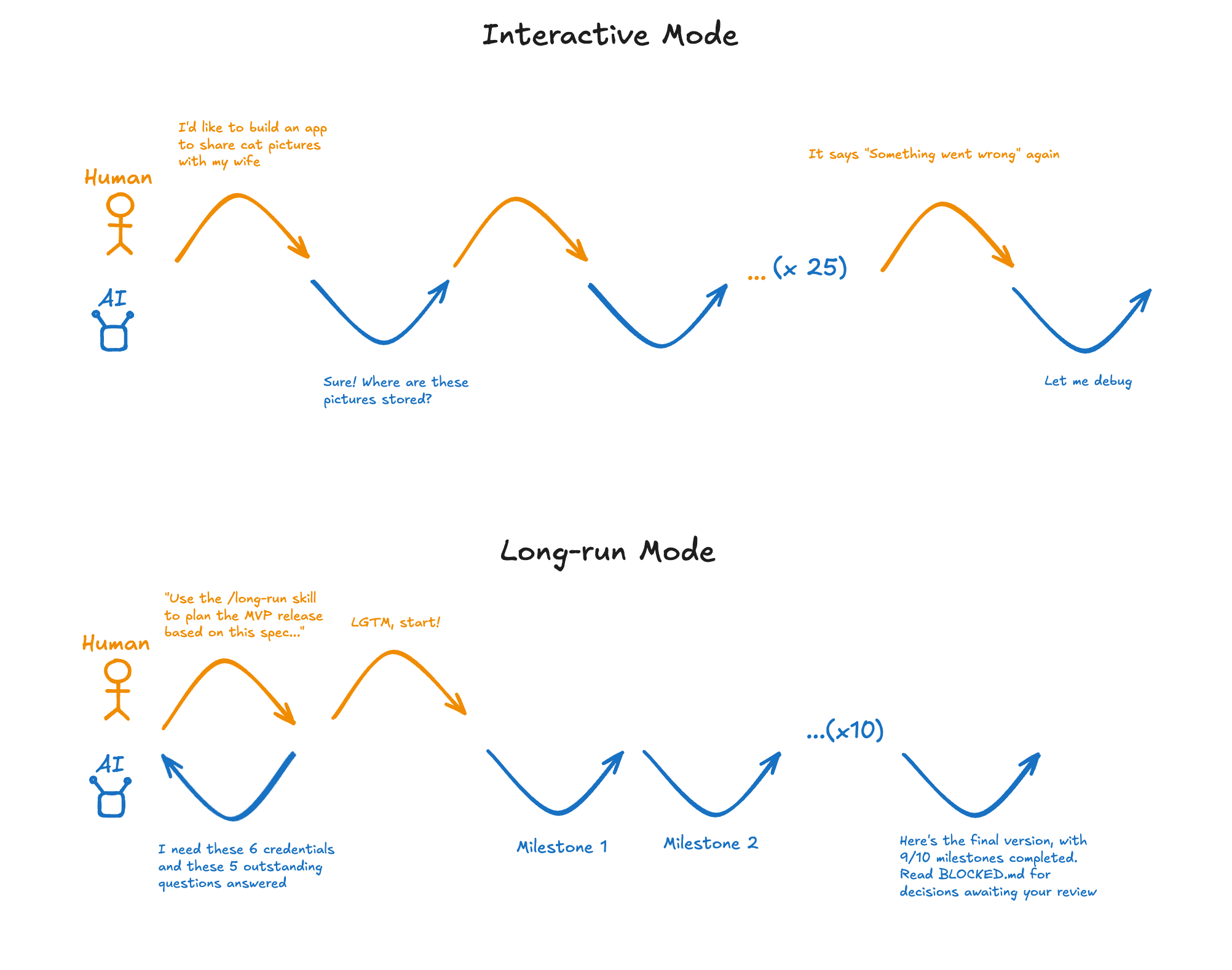
Most of my work with coding agents happens one prompt at a time: ask, wait, read, correct, repeat. Lately I've been trying something different for a couple of non-trivial greenfield projects. I hand Claude a whole roadmap upfront, it works on its own overnight, and I review the result in one sitting. People are calling these long-running agents.
These are great for chunky projects with a lot of moving parts: building an SDK, plus a demo app that exercises it, plus the docs, plus a small marketing site to sit on top. Or an agent that has to talk to five or six external tools and behave sensibly when any one of them returns something weird. The work itself isn't always hard, but there's a lot of it, and in the interactive mode you gradually descend into AI psychosis as you fix minor errors, the model runs out of context, you go back and forth for the nth time about a small choice etc.
The setup
The setup is weirdly simple. I spend a while upfront defining the problem and writing a spec. I ask Claude to break it into milestones. Then I run a /loop command every 30 to 60 minutes that picks up the next milestone. An orchestrator agent wakes up on each loop, reads the state of play, and dispatches work to worker agents. The workers write PRs and check in their work. The orchestrator reviews each one and either approves and merges it, or rejects it against some gates. If something blocks, it short-circuits and waits for me.
That's the whole thing. I didn't use any framework — I explained what I wanted and it just worked (minus that one time my brother stole my charger and my laptop battery died at 3am). I might look at some in future, but for now the loop plus a few markdown files on disk is enough.
Why not just run this over a single session?
-
The context window. When you're making lots of changes across lots of files, a single session runs out of room fast, and quality drops well before it actually fails. Splitting the work across many short-lived worker agents, each starting fresh and reading state from disk, gets around that. No one agent has to hold the whole project in its head.
-
Cost. There's a strange token arbitrage at the moment where the Max plans are far cheaper than the API billing (enjoy it while it lasts I guess!), so you can set this going without worrying about blowing through your usage limits or getting a nasty bill.
-
Attention. This is the one that matters most to me. I can spend a solid block of time defining the problem, pre-resolving as many blockers as I can think of, and handing Claude everything it needs. Then it goes away and works for twelve hours and comes back with a pile of stuff to review. I do the review in one chunk, write a couple of pages of markdown notes, and send it off on the next piece of work.
Compare that to the interactive shell or notebook style of coding agent: type a request, wait, read the response, paste some text back in, wait again. It's fun for a while. It feels like a video game. But it doesn't scale, because you have to stay at the terminal. If you're not there, nothing is happening.
Worse, it gives you the illusion of progress. You make a hundred small decisions that feel productive and don't actually matter much, instead of setting direction, nailing the functional requirements, and letting Claude pick the best tools for the job. It's way better at architectural choices than it used to be, and most of those small decisions are ones it can make fine on its own.
What makes it work
Three things, and skipping any of them breaks the run.
-
Give it everything upfront. All the credentials, all the access, a well-defined spec and roadmap. The orchestrator treats the roadmap as gospel and only executes what's in it, so an hour spent getting that right pays for itself many times over. This is also where you catch the blockers that would otherwise stop the run dead at 3am — a missing API key, an ambiguous requirement, two milestones that quietly depend on each other.
-
Keep the loop stateless between cycles. The orchestrator doesn't remember anything from one loop to the next. Everything that matters lives in a few files on disk that it reads back at the start of every cycle: the current state, a running digest, a list of anything blocked. Git is the source of truth for the code itself. Workers branch, commit, open a PR, and the orchestrator merges. The diff is the artifact. That file layout is most of the system, so it's worth seeing it laid out:
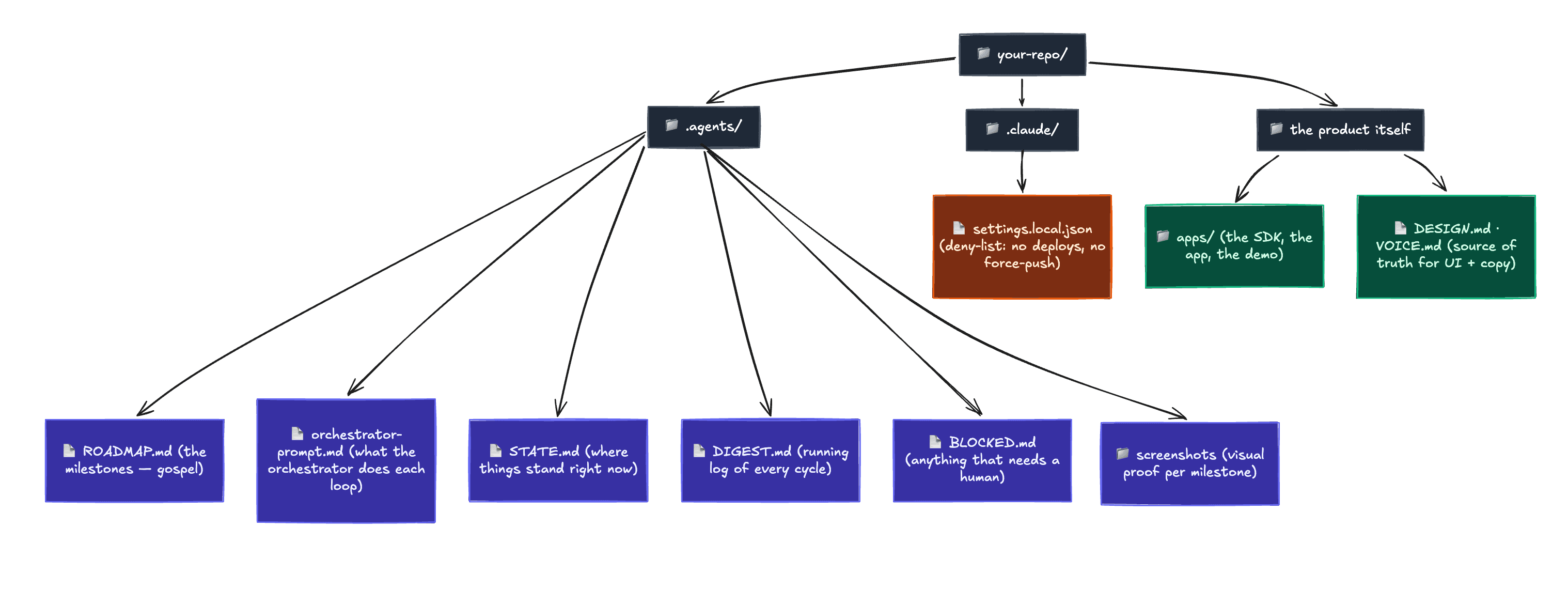
The whole orchestrator is reconstructable from those files at any moment. If a cycle crashes, the next one just reads the committed state and carries on. There's no hidden memory to lose.
- Make it verify its own work. This is the most important one. You have to give Claude the tools and the explicit instructions to verify every step itself. If it's building a UI, get it to start a local copy of the app and actually click through it. If it's sending a Slack message, check the message was received. In some cases you might have to set up demo accounts on specific platforms it can use. The more functional testing it can do inside its own build loop, the more time you save. Copy-pasting a console error back into the chat is an antipattern. You'll still do some testing by hand, but far less if Claude can QA its own work as it goes.
I've turned all of this into a skill, /long-run, if you want to try it. It builds the file structure above, audits your roadmap, wires up the gates and a kill switch, and hands you the kickoff command. It won't write the roadmap for you, which is the point: that part is yours.
A return to waterfall, sort of
What I didn't expect was how much this changes the level I work at with Claude.
When you're forced to define the end goal upfront, you stop thinking in individual tasks and features. You start thinking in milestones, goals, and releases. One good run can plan and execute what used to be a couple of weeks of work, or even a whole product version. As an ex-product manager who had to think through a couple of months of product iterations and always did functional testing rather than line-by-line code reviews, it feels like a very natural workflow.
Which means a bit of a return to waterfall might be on the cards. And waterfall actually has its place! It forces you to define a plan upfront, think through the edge cases, and agree on what "done" looks like before anyone writes a line of code. The reasons it fell out of fashion were practical: it was slow, and it took an enormous amount of human coordination to keep everyone marching to the same plan. Both of those problems are exactly the ones you can now hand to Claude. It does the coordination, and the slow part overnight. You keep the part waterfall was always good at, which is having a solid plan with dependencies and risks mapped out.
So the job changes. Less completing tasks, more setting direction and letting the thing run.

>_ Written By
John Reid